This is the fourth post in our series on Agentic Data Environments.
The previous two posts discussed branching agent environments: agents can try speculative actions on isolated state and discard branches that would damage the production database. While this handles destructive state changes, it does not enforce policies governing how an agent may use that state – particularly, records in a database.
Many important policies concern these data flows. Users may require that any released statistic containing their data must be aggregated over at least (K) users before disclosure. Federal education reports often require results to remain separated across protected groups while suppressing groups that are too small to release safely. Financial firms prohibit sensitive information from crossing internal information barriers between e.g., buy side and sell side. Accounting systems may require that every expense inserted by an agent be derived from an actual receipt rather than values that merely look plausible.
Existing guardrails are poorly matched to these requirements:
- Prompt-based rules delegate enforcement to the same unreliable agent performing the task.
- Access controls can block sensitive data entirely, but cannot permit useful computations while restricting particular combinations or outputs.
- Tool-call filters inspect the request before execution. They generally cannot determine which records contributed to the result or which transformations were applied during execution.
- Output filters and DLP checks can catch some sensitive values in a final output, but cannot establish whether an aggregate, summary, or inserted record was derived in an allowed way.
Ultimately, these data safety policies constrain derivations: the data flow from input records through transformations, joins, aggregations, and releases. Agent systems currently lack a way to express such policies, not to mention guarantee their enforcement during execution—which leaves developers asking LLM agents to magically never generate fake data and ensure tenant isolation (they will not). Organizations are therefore forced to choose between limiting what agents can do and relying on application-specific enforcement scattered across agent workflows.
To address this gap, we introduced Data Flow Control (DFC). DFC is a policy language and deterministic enforcement mechanism that ensures agents derive data safely. The rest of this post will demonstrate DFC through the example of a tax agent, compare DFC with controlling data flow with LLMs, and highlight several DFC policies and its ~0% overhead.
We are open sourcing DFC alongside some examples to get started. We are working with partners to integrate DFC into their deployments; contact cgs2161@columbia.edu if you are interested!
TaxAgent
In order for a tax preparation agent to be useful it must follow the law. Consider the sub-task of filing Schedule C deductions (something ~20% of US taxpayers do each year). Filers consider each receipt and deduct expenses that are business related.
The agent sees a database containing two tables: a full Receipts table and an empty Expenses table. The agent is tasked with adding an expense for every receipt, including a biz_use percentage to identify to what degree the expense is business related.

While performing this task, the agent must manipulate the data in a way that is:
- Law-abiding: Deductions must comply with tax regulation.
- Grounded: Agents cannot hallucinate and insert a non-existent receipt into
Expenses. So every row must be derived from a receipt. - Private: A single user’s receipts must never be publicly released. Any public release must aggregate receipts from multiple users.
The agent’s insert query breaks 26 U.S.C.§274(n), where: “Only 50% of meal expenses allowed as deduction.” Unfortunately, existing data safety mechanisms cannot stop the agent’s insert. We cannot create an access control rule that limits access to row 3 in Receipts because the agent must read every row for potential deduction. And we cannot create a CHECK constraint on Expenses because it would need to refer to the contributing cat column in the Receipts table. And the agent ignores the policy even if it is in the prompt!
LLMs Are Horrible for Checking Data Flow
One popular solution is to use LLM-based guardrails: a second agent verifies the first agent’s actions against desired policies. Unfortunately, agents are bad at checking policies and often ignore the data altogether. Further, the query’s data flow is invisible to the agent, so it doesn’t have access to the information it needs to evaluate data flow policies!
We ran an experiment where we fixed the data (synthetic receipts) and query (assigning a deduction to 10 of receipts while inserting into an expenses table). We asked two frontier models at several reasoning efforts to determine if 26 U.S.C.§274(n) was violated given a description of the policy, the query, and the results. 10 queries were run per setting, with 5 passing and 5 failing.
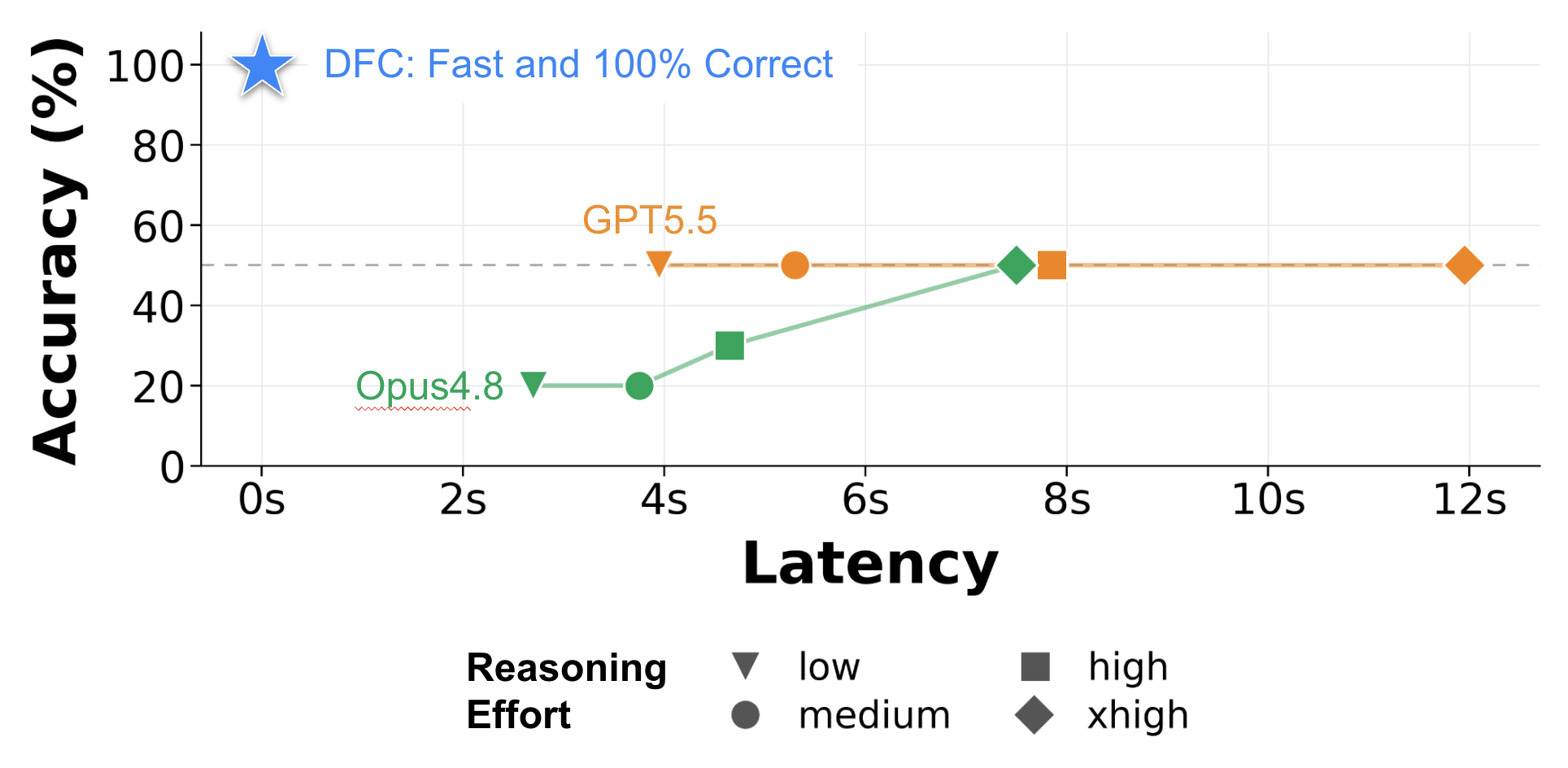
The above results show that checking a single policy for a single query takes seconds and has an accuracy of at best 50%. GPT 5.5 performs better than Opus, but it does so by rejecting every query without considering the data – clearly not the right approach in the real world where most queries are safe.
Relying on LLMs for policy enforcement is clearly a non-starter for database applications. DFC lets us push the enforcement accuracy to 100% and is near-free.
Data Flow Control Policies In Brief
To keep the post legible, we will explain DFC’s policy language by translating the three requirements (Law-abiding, Private, and Grounded) of the TaxAgent above.
Example 1: Law-abiding
SOURCE Receipts SINK Expenses
CONSTRAINT Receipts.cat != 'Meal' or Expenses.biz_use <= 50%
ON FAIL REMOVE
When the agent submits a query ℚ, we determine whether the policy should be applied by checking whether the SOURCE table Receipts is referenced in ℚ and if ℚ inserts or updates into the SINK Expenses. If so, then we ensure the policy’s boolean CONSTRAINT is true for the query’s output records. If not, ON FAIL will remove the violating output records.
The CONSTRAINT checks that if the inserted expense record is derived from a meal receipt, then its business expense must not exceed 50%. Violations will drop the offending expense record, and alert a warning to the agent.
Next, let’s consider a policy to ensure each insert is grounded. The purpose of groundedness is to avoid hallucination. For the moment, agents still confidently make the wrong decision when they believe they cannot access data.
Example 2: Grounded
SOURCE REQUIRED Receipts SINK Expenses
CONSTRAINT Receipts.id = Expenses.id
ON FAIL KILL
We want to make sure that expense records will never be hallucinated and are always derived from an actual receipt. The REQUIRED keyword ensures that any INSERT or UPDATE query into Expenses must read from Receipts. Thus, even if it generated an expense record with the same values as an existing receipt, it is disallowed if there is no derivation. This forces grounding.
The CONSTRAINT ensures that the output expense is derived by the expense with the same primary key id. If the constraint is violated, the entire query is KILLed and the error is raised to the agent.
These examples scratch the surface of the policy language, and our full preprint contains a number of features designed to be useful in real environments. A few examples include:
- Often policies should be conditionally applied: for instance, only applying to EU users. We allow policies to reference any data source that can be modeled as a relation, including transaction state, user and access control tables, agent memory in the database, and foreign data wrappers.
- Sometimes, a policy needs to make a semantic judgement, for instance that the receipt’s description looks like a meal or that a transaction seems anomalous. Constraints are normal boolean expressions, so policies can freely make LLM calls!
Enforcing Data Flow Control
At a high level, DFC policies are constraints over the provenance of a query’s output records, with additional features to support agent needs. Database provenance has decades of history, with beautiful theory and many system prototypes. Thus in principle, policy enforcement is straightforward: use a database engine that also captures record-level provenance during query execution, and simply feed the query output and provenance to a policy checker.
The problem is that capturing provenance is very expensive and can slow down a query by 100x or >1000x – even with the fast provenance capture engines our lab has worked on for almost a decade. In addition, it requires that the database engine supports provenance capture – and almost none actually do.
Thus, we enforce DFC in a database agnostic way by rewriting the query ℚ into ℚ’ that enforces the query as part of query execution. By piggybacking off of query execution, the marginal cost to evaluate the constraints is negligible. By rewriting the query outside the database, it runs on any database engine, including DuckDB, PostgreSQL, AWS Redshift, Snowflake, and any popular system.
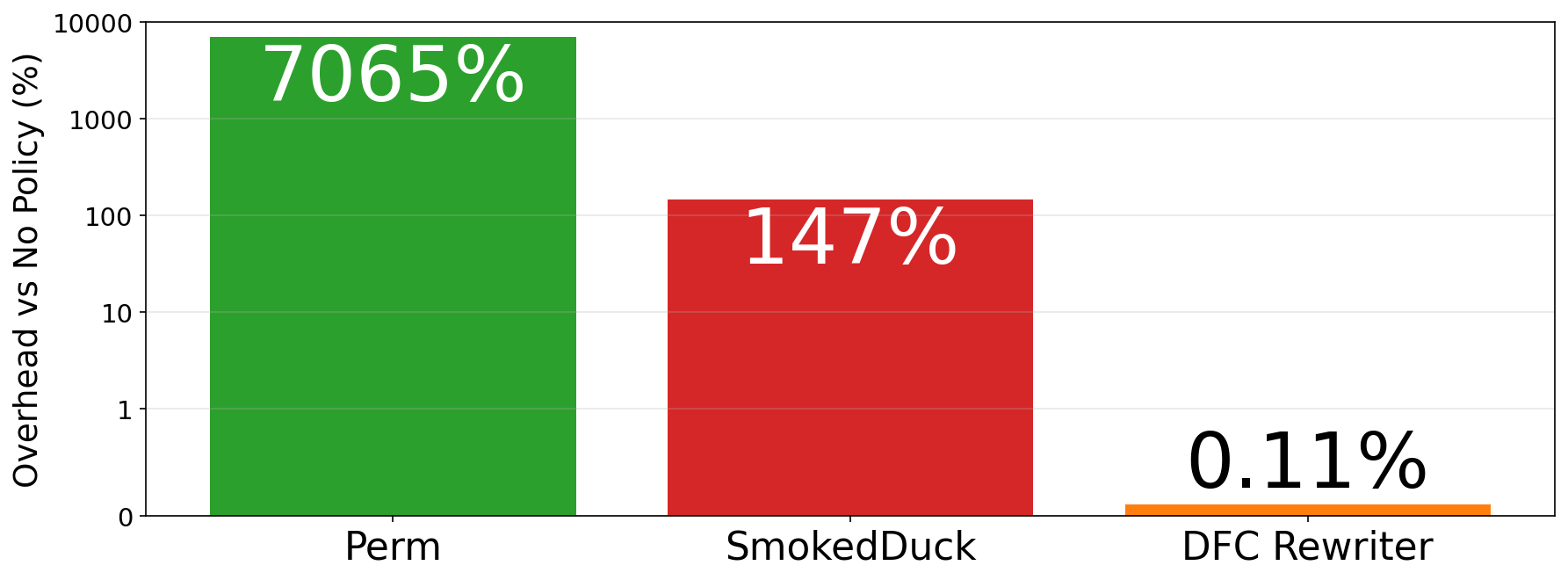
Below, we enforce a policy removing outputs where all contributing lineitems have quantity 0 and execute the TPC-H benchmark with scale factor 10. As compared to the state of the art methods to capture provenance Perm and SmokedDuck, the cost is almost free. A query that takes 100ms now takes 100.11ms but guarantees policy enforcement.
What’s Next?
Data Flow Control is a necessary guardrail so that agents can safely manipulate data. So, install DFC, try it out on your workload, and check out the DFC open source repo. We’d love any feedback you have! We’re also talking with early industry partners about using DFC in their products. If you have a use case then we’d love to talk with you.
Finally, we’re working on two important next research steps:
- Integrating with agent harnesses so that DFC policies can intervene on data flow between agent tool calls instead of only between database tables.
- Extending data flow control across multiple agent turns. For example, if
Receiptswere written to an intermediate table, then written toExpensesthen all DFC policies must apply.
If you’d like to learn how data flow control works, read our research papers. If you’d like to contribute, partner, or collaborate with us on data flow control, please reach out to cgs2161@columbia.edu.