TidalWave Benchmark Technical Report - External
Executive Summary
This report contains the findings and takeaways of the mortgage agent benchmark project, a collaboration between TidalWave and the NLP Lab at Columbia University in fall-winter 2025. We created a 90-question dataset based on 10 applicant personas spanning a range of realistic, natural questions expected to be asked to Tidalwave’s AI agent Solo by loan officers in the loan origination process. We find that SOLO with the Claude 4.5 backend (the strongest model available during initial development) outperforms vanilla Claude 4.5, achieving an F1 accuracy of 84.2 vs. 71.4 (+12.8). We also demonstrate SOLO-v2-beta (currently unreleased) achieves 88.0% F1 accuracy. We notice that SOLO achieves especially strong performance gains over baseline in boolean questions, indicating strong domain expertise. SOLO-v2-beta achieves performance gain over both SOLO in all other categories and over baseline in all categories. Overall, we demonstrate both SOLO and SOLO-v2-beta achieve strong accuracy on realistic queries, comparable to human performance.
Benchmark
We aimed to create a benchmark to evaluate the accuracy of Tidalwave’s AI agent Solo and related agents when responding to realistic questions by loan officers. To contain the scope of this benchmark to core SOLO chatbot features, we defined its scope as:
In Scope
- Single-turn QA following bank statement upload, parsing, and loading into loan application context
- Transaction retrieval
- Multi-transaction reasoning and pattern recognition
- Loan profile verification
- Objective questions
Future Work
- Multi-turn QA
- Document preprocessing
- PII leakage and red-teaming
- Action execution
- Subjective questions
- Corrupted data
Dataset Schema
The dataset consists of nine borrower personas constructed from fully synthetic bank statement data. Each persona includes a Uniform Loan Application Dataset (ULAD) file including all standard ULAD fields. Personas also include a list of transactions spanning up to two months in JSON format. Each persona is associated with ten questions.
Dataset Creation
A subject matter expert (SME) created each profile using fully synthetic data, then created questions associated with the profile based on historic chatbot use. The SME took care to modify profiles such that positive and negative examples were roughly balanced, usually by modifying the transaction list to include rare situations, such as inconsistencies compared to the ULAD.
Although synthetic data may follow a different distribution than real-world data, we chose not to use real world data due to privacy concerns. Even if real world data is scrubbed of PII, we are unaware of any scrubbing method robust to all deanonymization attacks, such as network cross-referencing. Furthermore, indirect PII, such as the address of an ATM, may be included in free text in the transaction description, requiring an even higher degree of scrutiny to detect completely.
During dataset creation, SMEs produced two versions of each question: one in natural language and one in an unambiguous, literal, and technical style. Noting that performance across models is not significantly affected by the question style, we choose to use the naturalistic style.
Example Questions
We choose questions from historical SOLO use data, ensuring coverage of diverse use cases. Some examples include:
Which list of deposits, if any, are considered as large deposits?
Which list of deposits, if any, could be of foreign origin?
Are there any recurring deposits that could be an undisclosed income source, not including cash deposits?
Evaluation
Answers to all questions in the dataset fall into one of three categories:
- Boolean (yes/no)
Do the payroll deposit entries match with the primary borrower’s employer names stated in employment history?
- Transaction list
Scan the provided bank statements for any recurring payments or debit transactions made to known BNPL providers.
- Account list
Are there any provided retirement accounts that can be used as a source of funds for the mortgage?
In order to assign partial credit to partially correct answers in transaction and account list questions, we use F1 as our primary metric:
\[F1 = \frac{2*P*R}{P+R}\]Where P is precision and R is recall. For boolean answers, we set F1 to 1 or 0 if the answer is correct or incorrect, respectively.
Models
We evaluate the current in-production SOLO agent through its API as well as Claude 4.5 using direct prompting. For direct comparison to baselines, we use Claude 4.5 as the backend foundational model for SOLO. We also evaluate SOLO-v2-beta, an unreleased agent currently under development. SOLO-v2-beta uses an undisclosed backend model.
SOLO
We configure the SOLO API to accept chat messages mapped to a specific persona from the dataset. SOLO receives the question directly, without a prompt template. Because SOLO answers in chat format, rather than the strict formatted output, we use a GPT-5-based post processor to convert SOLO’s answer to the correct format for evaluation. Although SOLO may use various tools to search and filter transactions, these tool calls and search results are not visible to the post processor.
Baselines
We evaluate Claude 4.5 direct prompting. To ensure correct formatting, we prompt the model with the expected answer format, then parse responses using regular expressions.
Prompt format
Question: {question}
Bank Statement: {context}
ULAD DU: {ulad_du}
Answer the question. {domain_expertise}Do not think out loud. {answer_instruction}.
Where answer_instruction is one of
Boolean
Return only yes or no. DO NOT output any other text.
Transaction List
Return ONLY a valid JSON list of matching TransactionID values, e.g.
["2-00037", "2-00049"], or [] if there are no IDs.
Account List
Return ONLY a valid JSON list of account numbers (last 4 digits only). e.g.
["1234", "5678"], or [] if there are no account numbers.’
Results & Discussion
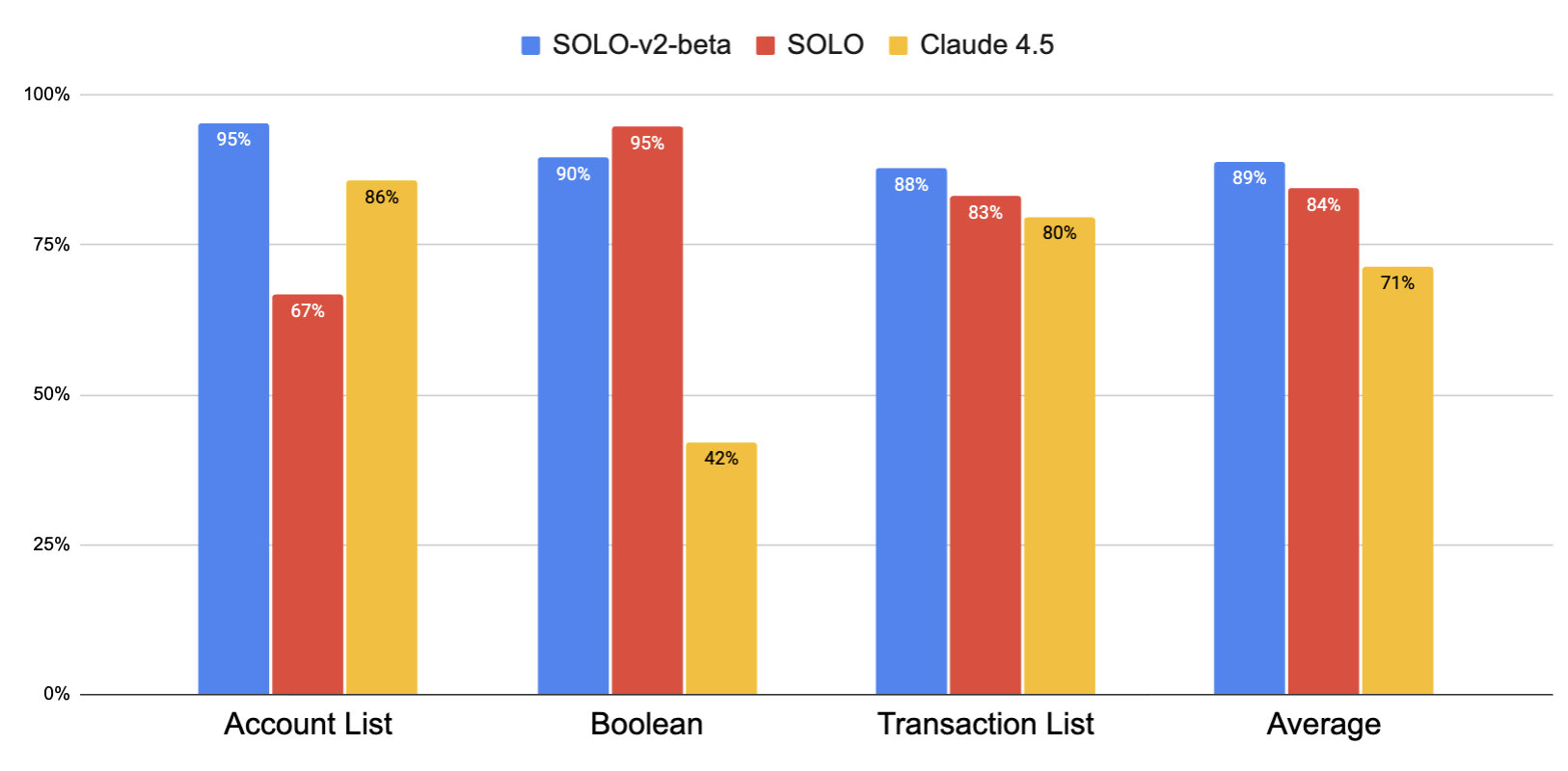
F1 accuracy for SOLO-v2-beta, SOLO (Claude 4.5 backend) and Baseline Claude 4.5
We observe that SOLO (84% accuracy) achieves substantial improvement gains on average over its equivalent Claude 4.5 baseline (71%). Although it loses some accuracy in account list type questions (67%), SOLO achieves extremely strong performance on boolean questions (95%). This indicates that SOLO has especially good domain expertise and excels at handling ULAD data.
We also observe uniformly strong performance by SOLO-v2-beta (89%) compared to Claude 4.5 (71%), and SOLO (84%). However, SOLO-v2-beta loses 5% accuracy compared to SOLO on boolean type questions. Overall, the strong performance of the currently deployed SOLO agent on this benchmark indicates it is suitable for real-world deployment, particularly when paired with human oversight.
Although strong, we note a systemic bias in SOLO-v2-beta where it tends to omit transactions.
.png)
SOLO-v2-beta failure modes. From top-right counterclockwise: answer is missing at least one transaction; answer is missing at least one transaction and includes at least one irrelevant transaction; answer contains at least one relevant transaction; boolean question is answered incorrectly.
Missing transactions appear far more often than extra transactions (58.1% vs. 29.8%), suggesting that SOLO-v2-beta is relatively conservative with its transaction inclusion. Qualitatively, we notice that SOLO-v2-beta sometimes misses transactions with by lesser-known vendors, such as BNPL provider Lightstream.
Appendix A: Dataset Statistics
A.1 Overview
The evaluation dataset comprises 93 labeled question-answer pairs spanning 9 test cases (cases 1-7, 9, and 10; case 8 is excluded). Each test case corresponds to a distinct loan scenario with associated bank statement documents. Questions are posed in both a natural-language form and a rephrased (technical) form.
A.2 Answer Types
Each question expects one of two answer types: a list of transaction IDs (id_list) or a boolean (yes/no).
| Answer Type | Count | % |
|---|---|---|
id_list |
67 | 72.0% |
boolean |
26 | 28.0% |
Boolean Answer Distribution
| Answer | Count | % of boolean |
|---|---|---|
| Yes | 20 | 76.9% |
| No | 6 | 23.1% |
ID List Answer Distribution
| Answer | Count | % of id_list |
|---|---|---|
| Non-empty (has transaction IDs) | 49 | 73.1% |
| Empty (expected answer is “none”) | 18 | 26.9% |
A.4 Transaction ID Statistics
Questions with id_list answers reference specific transactions by ID. The following summarizes the number of expected transaction IDs per question.
| Statistic | Value |
|---|---|
| Total transaction IDs referenced | 122 |
| Unique transaction IDs | 97 |
| Min | 1 |
| Median | 2 |
| Mean | 2.49 |
| Max | 10 |
The 97 unique IDs indicate that some transactions are referenced by multiple questions (e.g., a single large deposit may be relevant to questions about deposit sourcing, gift funds, and asset verification).
A.5 Task Labels
Each question is assigned one or more task labels indicating the type of analysis required.
| Label | Count | % of questions |
|---|---|---|
has_any |
56 | 60.2% |
transaction_consistency |
18 | 19.4% |
consistency |
11 | 11.8% |
statement_integrity |
11 | 11.8% |
metadata_consistency |
6 | 6.5% |
pooling |
1 | 1.1% |
Label definitions:
has_any— Identify whether specific transaction types exist (e.g., BNPL payments, large deposits, rental payments).transaction_consistency— Verify that transaction details are consistent across documents or with application data.consistency— Verify that borrower information (e.g., payroll, income) is consistent between bank statements and the loan application.statement_integrity— Check structural properties of the bank statements themselves (e.g., sequential dates, matching balances).metadata_consistency— Verify that metadata fields (e.g., account holder name, account number) are consistent across statements.pooling— Answer a question that relies on reasoning over multiple transactions.
A.6 Cross-Tabulations
Answer Type by Task Label
| Label | Boolean | ID List | Total |
|---|---|---|---|
has_any |
1 | 55 | 56 |
transaction_consistency |
6 | 12 | 18 |
consistency |
9 | 2 | 11 |
statement_integrity |
10 | 1 | 11 |
metadata_consistency |
1 | 5 | 6 |
pooling |
0 | 1 | 1 |