This is the second post in our series on Agentic Data Environments. It describes a newly released Branchable Database Benchmark called BranchBench and select results from our arXiv paper.
Update: We’ve been grateful to see the community engaging with BranchBench. DoltHub wrote a detailed response — Branch Bench: Database Benchmarking for Agentic Workflows — where they analyzed their results, acknowledged the performance gap, and committed to integrating BranchBench into their standard performance tracking. Thanks to Aaron and the DoltHub team!
Database branching will soon shift from developer convenience to fundamental agent infrastructure.
Today, a human might create one branch to test a migration, and many of today’s agent workflows mimic this linear approach. Future agents will create thousands — forking a candidate state, mutating it, evaluating the result (perhaps against other branches), pruning irrelevant states, and repeating. The database becomes the agent’s state management for safe exploration.
That shift changes the workload from “more queries” to a different shape of workload.
We built BranchBench to understand a simple question: can today’s branchable databases handle that shape?
Agents Need Alternate Realities
Agents are starting to use databases as more than passive storage. A database can become working memory: a place to try an action, inspect the result, keep promising states, discard bad ones, and compare alternatives before committing anything back to the main state.
Branching is appealing because it gives agents isolated, mutable worlds. They can explore without corrupting production state, compare outcomes before committing, and preserve evidence about how they got there.
The branch structure varies wildly depending on the agent and application. Some workloads create shallow fanouts to compare many independent alternatives. Others create deep speculative chains. MCTS-style agents maintain wide trees, prune weak paths, and expand promising ones. Each node can correspond to a database-backed state.
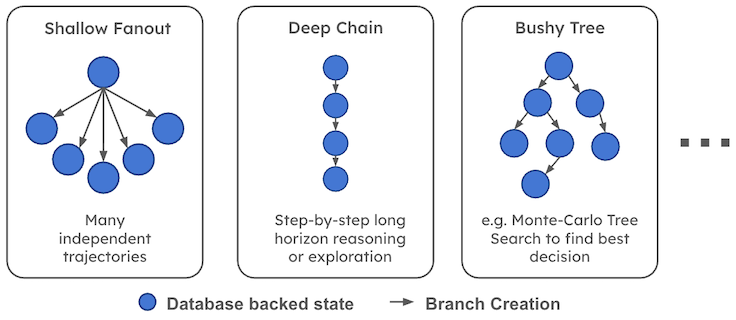
We Are Far From Where We Need to Be
A branchable database for agents needs two properties at once:
- Branching agility: create, connect to, switch between, and delete many live branches cheaply.
- Branch-local performance: run reads, joins, writes, schema changes, and indexes inside each branch, ideally logically and physically isolated.
Ideally, a branchable database for agents would sit in the upper-right of this design space: fast, scalable concurrent branching with fast branch-local DML and DDL. The systems we measured instead expose a trade-off. Systems that preserve strong branch-local performance often make branch management expensive. Systems with lightweight branching often pay heavily on branch-local data operations.
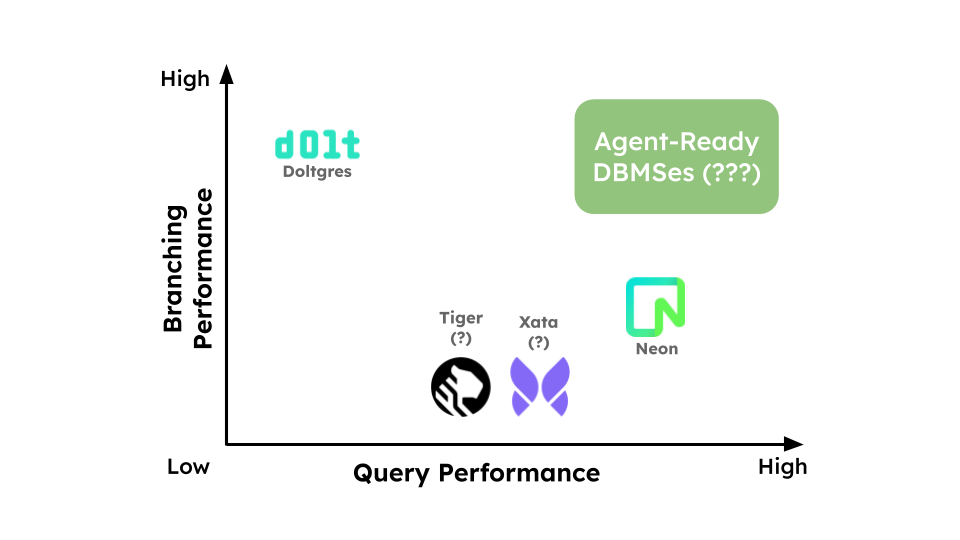
In fact, even the basics are hard. Agentic workloads need dozens, hundreds, or thousands of live branches, not just a branch abstraction on paper. In our experiments, systems hit practical limits quickly: active-branch caps, expensive branch creation, slow connect/switch operations, or degraded reads inside heavily branched histories.
“Supports branching” is not enough; agents need branching to be cheap, concurrent, and query-efficient.
We Built BranchBench to Measure Agentic Branching
BranchBench is a benchmark that evaluates the operations that future agents will likely stress, including:
- Branch shape: deep chains, wide fanout, pruning, and long-lived branch trees.
- Branch lifecycle: create, connect, switch, delete, and compare branch states.
- Branch-local work: point reads, range scans, writes, data cleaning, joins, and aggregations.
- Schema work: migrations, views, partitioning, and indexing.
- Cross-branch analysis: compare outcomes across speculative states.
The benchmark currently includes five ready-to-run workflows with configurable branch shapes, SQL schemas, and query templates. It is also extensible: users can define new workflows through protobuf configs and plug in their own schemas, DML, and DDL operations.
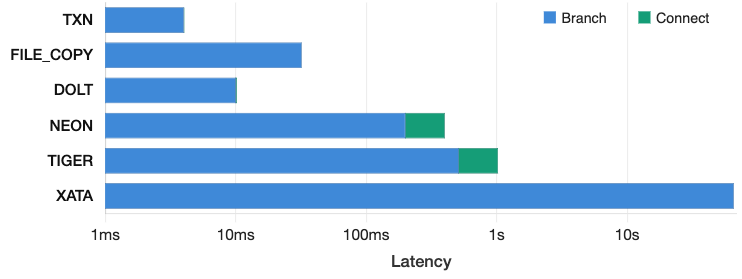
When we ran experiments in March, existing systems could not consistently finish all proposed workflows within a two-hour timeout. TigerData and Xata did not run reliably enough to draw meaningful conclusions. Neon and Dolt completed enough of the benchmark to reveal core trade-offs.
Do you have a branchable database, a workload that creates many candidate states, or an agent that needs safe exploration over data?
Reach out at ra3448@columbia.edu →Zooming Into One Workload: MCTS
Let’s focus on Monte Carlo Tree Search (MCTS), a popular agent exploration algorithm that pushes branching capabilities hard. The number of live branches grows over time because the agent must keep promising partial trajectories around while it explores their descendants. Branches are created repeatedly, mutated locally, queried for evaluation, and only later pruned or discarded.
Neon and Dolt are limited in opposite ways.
Neon executed branch-local reads and joins much faster, even with network latency to its hosted service. But branch management became the bottleneck:
- Branch creation was up to 25× slower
- Branch switching was up to 1500× slower
- The workload hit Neon’s 20-active-branch limit
Neon documents this as a soft limit, but for workloads that require many concurrent live branches, the cap is a practical architectural constraint.
Dolt had the opposite profile. Branch creation and checkout were cheap metadata operations over versioned roots — attractive for workloads that create many speculative states. However, larger reads and joins dominated runtime. In read-heavy macrobenchmarks, Dolt spent most of its time in branch-local data operations rather than branch management.
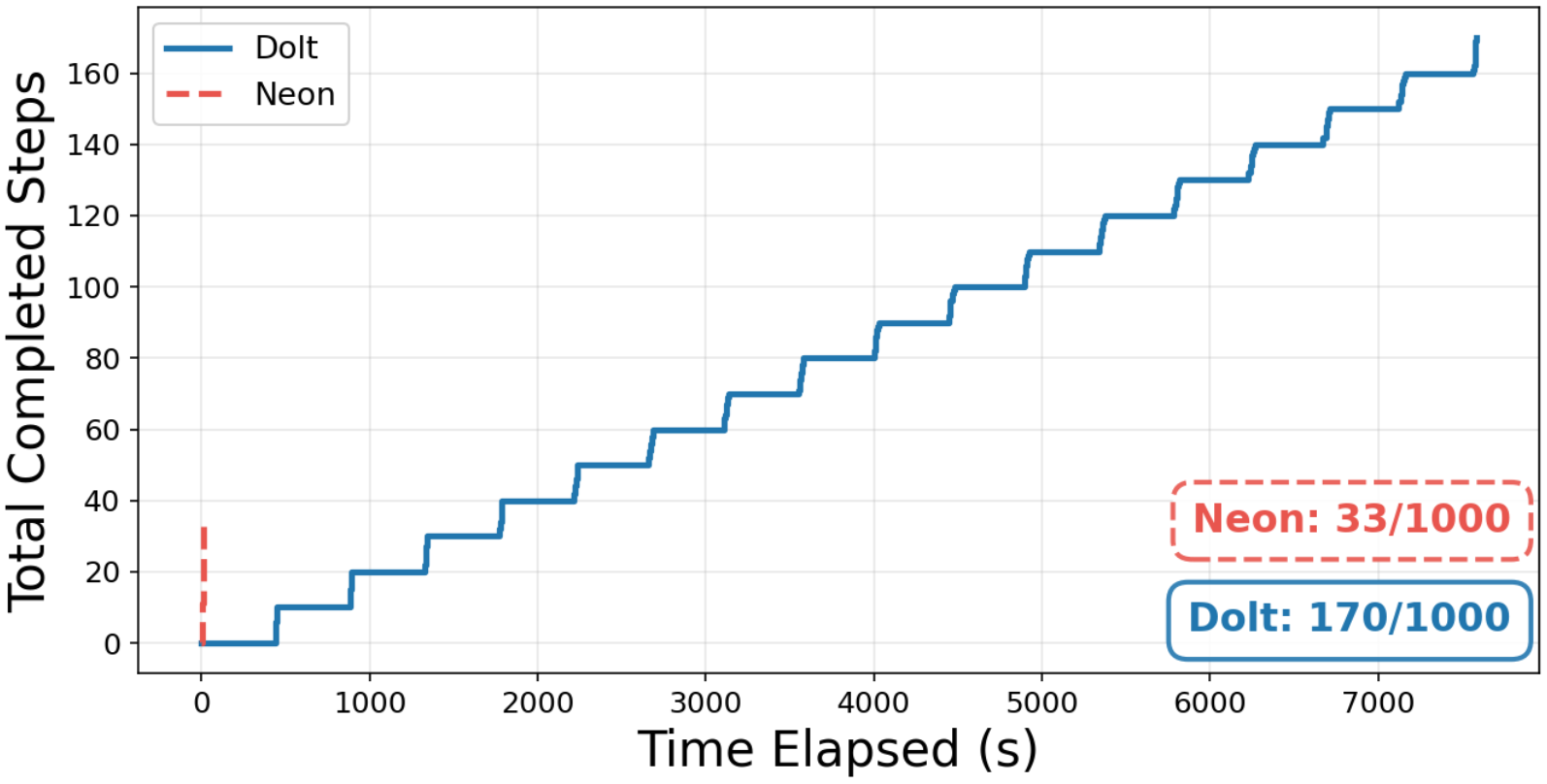
For a detailed analysis of branch metadata costs versus branch-local data and schema-operation costs, see the full paper.
What Comes Next?
Agentic applications are still early, so today’s production workloads do not yet fully stress branchable databases. That is why BranchBench is parameterized: we can vary branch count, depth, fanout, mutation type, read shape, pruning behavior, and concurrency to probe where systems break before real deployments get there.
Our goal is not to declare winners, but to anticipate future workloads and make trade-offs visible.
If agents are going to plan, repair, simulate, test, and safely explore over real data, they need databases that can support thousands of cheap alternate realities without giving up normal query performance. That system does not exist yet.
We want to build the benchmark with the community
- Bring workloads! If you have an agent that writes to a database during exploration, training, simulation, repair, planning, or evaluation, we would like to understand its workload shape.
- Bring backends! If you are building a branchable database, storage engine, versioned relational system, or research prototype, we would like to benchmark it.
Contributions, issues, and pull requests are welcome at github.com/ElaineAng/db-fork. To discuss further, reach out at ra3448@columbia.edu.
Next in the series: Checkpoint-lite — giving agents a rewind button for the full live environment, not just the database.