This is the first in a series of posts on Agentic Data Environments, based on our position paper from Columbia University’s Data, Agents, and Processes Lab (DAPLab).
Over the past several months, OpenClaw showed the world the potential for agentic automation: a personal AI that runs locally, clears your inbox, manages your calendar, executes shell commands, and extends itself with new skills – all via WhatsApp. For an end user managing their own data, this was a step change.
But deploying at enterprise scale, against shared systems of record, is a different problem altogether. When an agent mutates data on behalf of many users, failures have wide-ranging effects before they can even be detected:
- Cursor’s agent deleted PocketOS’s production database via a single rogue API call. So did Replit’s agent last July even when instructed not to.
- A 13-hour AWS outage was caused by Amazon’s own Kiro agent autonomously rebuilding a production environment.
- A zero-click ChatGPT vulnerability silently exfiltrated Gmail data from within OpenAI’s own cloud infrastructure.
This goes beyond the risks of using AI on one’s own systems—increasingly, there are legal liabilities for the downstream effects on others. New York proposed Senate Bill S7263, which would hold AI companies directly liable when agents cause harm when impersonating licensed professionals. Meanwhile, GDPR fines have reached €530M and the EU AI Act adds penalties up to €35M. These aren’t edge cases. They’re the predictable consequence of deploying agents that can write to systems designed only to be read by careful humans.
Fundamentally, we believe that smarter models and agents are not enough. The more important question is what guarantees the environment that the agent executes within needs to provide.
The Cost Asymmetry
The value proposition of agentic automation can be stated simply:

Benefits accrue over time as automation shows speed, scale, labor savings, and new opportunities. In contrast, Costs are abrupt, unexpected, and effectively unbounded today: deleting a production database, leaking sensitive data, an illegal filing, or bringing down a data center. Prospect theory shows that humans weigh losses far more heavily than gains, and this ultimately shapes adoption in practice. The risk of a failure suppresses the willingness to adopt far out of proportion to its likelihood.
Thus, “more reliable” or “more safe” is not sufficient. If catastrophic outcomes remain possible, adoption stalls regardless of how accurately or quickly the system performs in the common case. Trustworthy and safe automation requires guarantees instead of best-effort.
From Read-Only to Read-Write
Current AI agents – NL2SQL systems, RAG pipelines, analytics assistants – are largely read-only. A tax reporting agent retrieves financial records to estimate revenue, synthesizes them, and returns an answer. Its mistakes produce wrong answers.
The same agent becomes fundamentally different when it manages and files taxes rather than reporting them: it reconciles discrepancies, applies tax logic, overwrites prior filings, and submits legally binding documents. These actions write data and are consequential; the errors lead to outages, regulatory penalties, lawsuits, or compliance violations. This shift from read to read-write is the fundamental challenge.
From Agents to Data Environments
Most safety work focuses on the agent: better reasoning, better guardrails, better prompting. These are useful but not sufficient. The deeper issue is that the environment agents execute within was not designed for autonomous write access.
Agents operate within computing systems — databases, file systems, APIs, configuration systems, external services — designed for humans that act slowly, intentionally, and with contextual judgment. Agents act at machine speed across arbitrary system boundaries, and a single action can trigger cascading effects across multiple subsystems before anything is detected. The current stack provides no guarantees against this: access control governs who can touch data, integrity constraints govern what gets stored, but neither governs how data flows and is used during agentic execution.
Agents also remove structural accountability. When a human employee makes a consequential mistake, there is a clear chain of responsibility. Agents simultaneously cannot be held accountable and give users a target to deflect accountability. The risk has to be absorbed somewhere, and we believe it is the environment’s responsibility: before actions are taken rather than after damage is done.
The Need for Agentic Data Environments
We believe safe agentic automation demands a new class of infrastructure: Agentic Data Environments (ADEs).
Where today’s data systems passively serve an agent’s requests, Agentic Data Environments actively manage and govern the stateful substrate (e.g., databases, file systems, memory APIs, processes, etc) that the agent executes. They serve two critical functions:
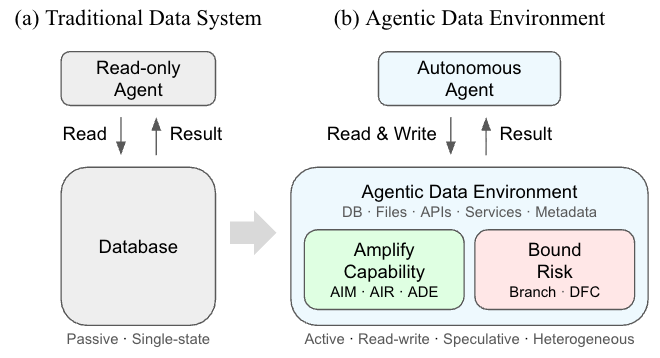
Amplify Capability. To increase the benefits of automation, agents must access and reason over the right information. Agent failures are increasingly information rather than reasoning failures. The responsibility of the data environment is to manage, find, elicit, and deliver the right information, in the right representation, at the right time, for the right agentic task.
Bound Risk. Agents need the freedom to try consequential actions without negative consequences. The responsibility of the data environment is to allow agents to aggressively explore while guaranteeing that the environment state and data remains protected.
Upcoming in the Series
This is the first in a series of posts that we will release over the next two weeks that lays out a research agenda for Agentic Data Environments.
To bound the risks, we will introduce:
- Branching for Agent Exploration: why agents need speculative execution at the database and OS level, what our BranchBench results reveal about how badly current systems fail, and what a branch-native architecture looks like.
- Data Flow Control (DFC): the missing safety primitive that neither access control nor LLM-based policy checking provides, and how provenance-based enforcement can deliver deterministic guarantees at near-zero overhead.
To amplify capabilities, we will introduce:
- Agentic Information Management (AIM): when you already have the data, but it’s in the wrong form. We show why RAG is the wrong default for agent memory, and how task-aware, structured representations turn raw sources into capabilities that agents can reliably use.
- Exploratory Question Answering and Agentic Information Retrieval (AIR): when the data exists, but is in a huge data lake with thousands or millions of documents/datasets, how to even find the useful information? We show why agents fail to find the evidence they need in real data lakes, the gap between retrieval and agent reasoning, and the need for new evaluation and systems.
- Agentic Data Elicitation (ADE): when the data doesn’t exist yet. We show how agents can surface latent signals by inspecting systems, collecting traces, and running controlled experiments, turning implicit knowledge into reusable artifacts.
The goal is not just better agents but a better environment for agents to operate within – one that both amplifies what they can do and bounds what can go wrong. These two are tightly coupled: richer capabilities require broader access to data and more aggressive exploration, which increases risk; stronger safety guarantees, in turn, enable agents to explore and act more freely. Agentic Data Environments bring these together by preparing the right information for agents while enforcing how it can be used and how state can evolve. That is the read-write problem, and it is the central challenge in data management for agents.